xcPEP Business Continuity and Disaster Recovery (BCDR) Policy
1. Purpose and Scope
This Business Continuity and Disaster Recovery (BCDR) Policy outlines Advanced Structures India Private Limited's strategy to ensure the continuous availability of the xcPEP SaaS platform and the rapid recovery of critical business operations in the event of a major disruption or disaster. The policy covers all critical services, infrastructure, and associated processes.
2. Definitions
Disaster: A sudden, unplanned event causing widespread damage or destruction, significantly disrupting normal operations.
Business Continuity (BC): The ability of an organization to continue critical business functions during and after a disaster.
Disaster Recovery (DR): The process of resuming normal business operations after a disaster.
Recovery Time Objective (RTO): The maximum tolerable duration of time that a computer system, network, or application can be down after a failure or disaster.
Recovery Point Objective (RPO): The maximum tolerable amount of data that can be lost from an IT service due to a major incident.
3. Roles and Responsibilities
BCDR Committee: A cross-functional committee responsible for overseeing the BCDR program.
Incident Response Team (IRT): Responsible for executing the DR plan during an incident.
Departmental Leads: Responsible for implementing continuity plans for their respective business functions.
4. Business Impact Analysis (BIA)
A comprehensive Business Impact Analysis (BIA) is conducted regularly to:
- Identify critical business functions and supporting IT systems of xcPEP.
- Assess the potential impact of disruptions on these functions.
- Determine the RTOs and RPOs for each critical function, prioritizing recovery efforts.
5. Disaster Recovery Strategy (AWS-based)
Our disaster recovery strategy leverages AWS's global infrastructure as depicted in the xcPEP Backup and Disaster Recovery Strategy diagram below: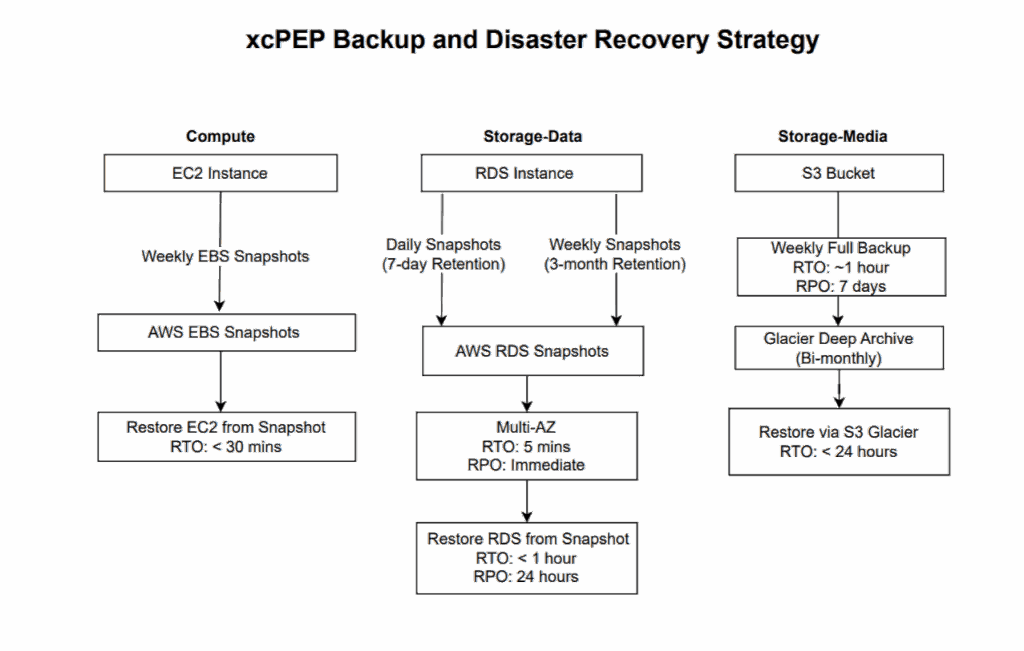
Disclaimer: This diagram outlines xcPEP's current approach to data backup and recovery. The information provided is "as is" and for general informational purposes only. It is not intended to create any warranties or commitments regarding the performance, functionality, or availability of the xcPEP platform or its underlying infrastructure. Our systems and procedures are continuously monitored, improved, and subject to change without prior notice. We encourage you to consult our latest Trust Center documentation for the most accurate and up-to-date information.
Compute (EC2 Instance) Recovery:
- Weekly EBS Snapshots: Weekly snapshots of EC2 instances are taken to ensure point-in-time recovery.
- AWS EBS Snapshots: These snapshots are stored in AWS EBS.
- Restore EC2 from Snapshot: In the event of a compute failure, EC2 instances can be restored from a snapshot with an RTO of less than 30 minutes.
Storage - Data (RDS Instance) Recovery:
- Daily Snapshots (7-day Retention): Daily snapshots of RDS instances are taken with a 7-day retention period.
- Weekly Snapshots (3-month Retention): Weekly snapshots of RDS instances are taken with a 3-month retention period for longer-term recovery.
- AWS RDS Snapshots: These snapshots are stored in AWS RDS.
- Multi-AZ (Availability Zone): For critical services, we utilize Multi-AZ deployments within AWS, ensuring high availability and a low RPO (immediate) and RTO (5 minutes) in case of an AZ failure.
- Restore RDS from Snapshot: In the event of an RDS instance failure, data can be restored from a snapshot with an RTO of less than 1 hour and an RPO of 24 hours (for snapshot-based recovery, distinct from Multi-AZ).
Storage - Media (S3 Bucket) Recovery:
- Weekly Full Backup: A weekly full backup of S3 buckets is performed with an RTO of approximately 1 hour and an RPO of 7 days.
- Glacier Deep Archive (Bi-monthly): For long-term, cost-effective archival, data is moved to Glacier Deep Archive bi-monthly.
- Restore via S3 Glacier: Restoration from S3 Glacier is available with an RTO of less than 24 hours.
General Failover Procedures: Detailed, documented procedures are maintained for initiating failover to the DR site, covering databases, application instances, networking, and other critical components. Automated failover mechanisms are implemented where possible.
Fallback Procedures: Procedures for safely returning operations to the primary site after recovery.
Recovery of Specific Components: Comprehensive plans exist for the recovery of all critical components, including databases, application servers, network configurations, and storage.
6. Business Continuity Plan
Our Business Continuity Plan addresses:
Communication Plan: Internal and external communication protocols during a disaster, including notification to customers about service status and recovery progress.
Workforce Preparedness: Procedures for remote work capabilities and alternative work locations for employees.
Supplier Management: Contingency plans for critical third-party service providers.
Essential Operations: Strategies to maintain essential business operations while core IT services are being restored.
7. Testing and Exercising
Frequency: BCDR plans and procedures are regularly tested at least annually through comprehensive disaster recovery drills and tabletop exercises.
Types of Tests: Tests include simulated failovers, data restoration drills, and communication exercises.
Review and Improvement: Results from testing are meticulously reviewed, and lessons learned are incorporated into plan updates to ensure continuous improvement.
8. Policy Review and Updates
This BCDR Policy is reviewed and updated at least annually, or more frequently in response to changes in our infrastructure, business operations, or identified risks.